Distributed state and network topologies in chat systems
[This is post 3 about designing a new chat system. Have a look at the first post in the series for more context!]
The funny thing about trying to design communications protocols seems to be how much of the protocol’s code ends up just dealing with networking – or rather, that certainly seems to be one of the main things a design is focused around. We’ve talked previously about federation, and the benefits and downsides associated with having a completely open approach, as well as the issues of distributed state and spam that inevitably come up. In this blog post, I want to propose and explore the networking and federation parts of an idealistic new chat protocol, and attempt to come up with my own solution1! (If you’re just interested in a summary, skip past the following ~2,000 words to the “Conclusions” header.)
The basic model: IRC server linking
I’m going to assume, for the purposes of this blog post, that “full mesh” networking is a bad design choice (as discussed in the previous post). This is partially because there are already protocols like ActivityPub, XMPP, and Matrix that use full mesh networking, so it’s worth exploring something different for a change; I also believe that full mesh is a rather inefficient way to run a network, but you’re free to disagree with me on this2.
So, let’s start with the very simplistic network model used by IRC: a simple spanning-tree arrangement, where servers are linked to one another with neither loops nor redundancy. This looks a bit like this:
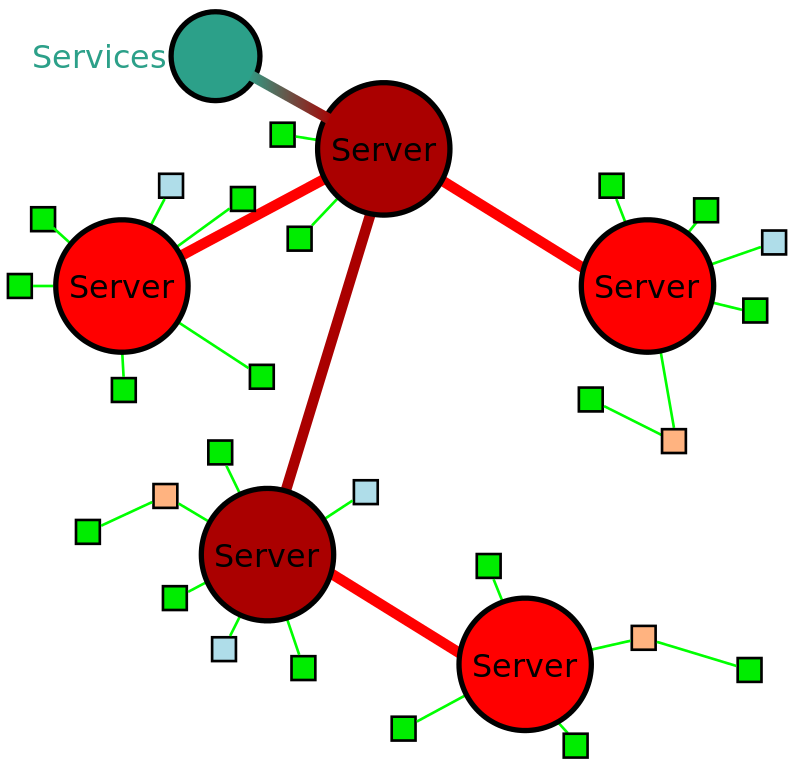
This is stupidly simple for server implementors to implement. Here’s how it works: if you’re connected to servers A, B, and C, and you receive a message from server A, you just process the message, and send it on to servers B and C (i.e. the rest of the network). You don’t even need to worry about deduplication, because there’s no way you could get sent the message again (if all the servers behave, that is3). As Rachel Kroll notes in “IRC netsplits, spanning trees, and distributed state” (a post from 2013 – go and read it, it’s pretty interesting!):
…the entire network is a series of links which themselves constitute a single point of failure for people on either side of it. When something goes wrong between two servers, this manifests as a “netsplit”.
Whole swaths of users (appear to) sign off en masse when this happens, and then will similarly seem to rejoin after the net relinks, whether via the same two servers or through some other path.
This was the situation back in the ’90s, and it’s still happening today.
She then goes on to talk about a number of ways in which this situation could be rather trivially avoided – for example, using the Spanning Tree Protocol, which uses an algorithm to detect and avoid possible loops between interconnected network switches, such that you can have a bunch of redundant links that only need to be used when one of the links fail, or by simply using some smarts to tag messages with an ID and the list of servers they’ve already been through to avoid duplicates.
This all makes things less than stupidly simple, but there’s a difference between necessary and unnecessary complexity. As Rachel notes:
There are solutions to problems which don’t exist, and then there are assortments of technologies which might be useful for problems which technically exist, but for which nobody may care about fixing. I suspect the whole IRC netsplit thing is a case of the latter.
1-to-1 vs group chats
So, delivering messages from one place to another is all fine and good, but the real fun starts when you try and set up a group chat, which involves multiple people, and – quite crucially – some idea of distributed state, which isn’t the easiest thing to achieve. This state is required for all sorts of common features to work – from things as simple as setting the name and topic of the chatroom to being able to give people administrator powers, kick and ban users, etc. Getting this wrong has real consequences; in the olden days, netsplits could lead to IRC takeovers, where users would gain administrator access on one side of the netsplit (perhaps due to the channel having no users left on that side, which leaves the first user to rejoin with admin powers) and then retain it after the network reformed, with disastrous consequences.
The Matrix protocol, mentioned before, is essentially a massive effort to solve this problem through modeling state changes that occur in a chatroom as a directed acyclic graph, and running the state resolution algorithm to resolve multiple conflicting pieces of state after network partitions (or at any time, really). This algorithm is pretty complex stuff (and it seems like they came up with it mostly on their own!); I’ve stated in the first blog post of this series that doing things this way is ‘questionable’ – but it was later pointed out that my view was somewhat out of date4, so I’m not really an authority on this.
The Matrix approach relies on the room state being independently calculated by each participating server, using the algorithm to determine which events to accept and reject – which makes servers not really depend on one another that much, at the cost of some additional complexity. It does, however, mean that rooms continue to operate – and can accept state changes – even when network partitions occur; the state resolution algorithm will eventually restore consistency. In other words, this satisfies the AP parts of the CAP theorem, with eventual consistency (things will eventually be consistent after servers reconnect, but are not, of course, consistent all the time).
XEP-0045 (XMPP’s group chat extension), on the other hand, is at the complete other end of the spectrum: group chats seem to be exclusively owned by one server, and are unusable if said server goes down. This obviously makes things a lot simpler, but means that a group chat – even if it were to have hundreds or thousands of participants – is entirely reliant on that one server to relay messages and handle state updates, which is a massive single point of failure. Other servers couldn’t possibly step in under this model, because otherwise the group chat would be open to attack; any random server could jump in and claim ownership of the room, resulting in chaos similar to that of the IRC takeovers mentioned earlier.
What are we defending against?
If we lived in a world where everyone was honest and well-meaning, the lives of chat protocol designers worldwide would be made much easier. In this world, we could just blindly accept whatever people said had happened to the room, from any server that sent us a message about it – if you were to list the things that could happen, it might look like:
- A malicious actor could introduce their own server to a group chat, and manipulate its state in unwanted ways – like making themselves administrator without the consent of the prior administrators, or ‘resetting’ it to an earlier time when they weren’t banned, or something like that.
- A malicious actor could introduce their own server to a group chat, and start sending large volumes of spam into said group chat.
- A malicious server owner could take control of certain important user accounts on their server, like accounts that have administrator powers in big popular rooms, and use those to take control of the rooms by sending legitimate messages coming from that user.
These are all things that systems like Matrix, XMPP, IRC and others try to prevent. IRC doesn’t let people introduce their own untrusted servers into an IRC network, which makes things a lot easier; the others do allow for this possibility, meaning they now have to decide what information is trustworthy and what is not, using a varied set of methods to determine this.
A ‘middle way’
Through our earlier comparison, it becomes apparent that there’s a sort of spectrum of how much trust the protocol requires you to have in other people and their servers. XMPP is at one end, with “trust one server absolutely, and no others”; Matrix is at the other, with “individually verify the room state on each participating server, with a fancy algorithm that helps keep things in check”. With things laid out like this, is it not worth asking the question of whether our new chat standard can try an approach somewhere in the middle of those two?
How about trusting some servers – more than one, to provide a degree of redundancy, but not going as far as allowing any server to change the room’s state? I posit that, in practice, users are having to do this anyway in protocols like Matrix, simply because pretty much any protocol that exists today is vulnerable to problem (3) from the earlier list5. So, for each group chat, we could define a set of “sponsoring servers” that are responsible for upholding law and order in the chatroom.
The sponsoring server model
Rather like in XMPP, all traffic for the group chat has to go through one of the sponsoring servers. If you want to send a message, ban someone, change the topic, or do anything, you have to send your message through a sponsoring server first. These servers rebroadcast the message you’ve sent to other connected servers, after checking that you’re allowed to make that change given their current view of the world.
Other servers can now authenticate messages very easily: if the message was sent by a sponsoring server, it’s valid, because we trust the sponsoring servers to validate everything for us. If it wasn’t, it isn’t. Spam, therefore, can be curtailed; since servers won’t accept messages that don’t come from sponsoring servers, sponsoring servers can do whatever they want to make sure that messages aren’t spam before passing them on, like asking new users to fill out a CAPTCHA or whatever.
What about distributed state?
The Paxos consensus protocol – actually something mentioned by Rachel Kroll in the cited blog post from earlier6 – is a tried and tested way to generate consensus among a network of servers, some of which may disconnect occasionally, go offline, or otherwise fail. It’s not guaranteed to always make progress, especially not when some of the servers are being evil (although a variant, called Byzantine Paxos, is supposed to fix this), but it’s reliable enough to be used in a number of prominent places, such as in various Google, IBM and Microsoft production services. Paxos is also not the only consensus protocol out there – the Raft consensus protocol is another, apparently known for being easier to implement7, which has similar properties. Here’s a cool Raft visualization!
As you can probably see, we can use Paxos or Raft to resolve state among our sponsoring servers, in a way that’s tolerant of these servers occasionally going down; as long as a majority remains (or whatever criteria the chosen consensus protocol specifies), the group chat will continue to operate in a safe manner. We trust all of our sponsoring servers, so we don’t have to worry about them trying to break the consensus protocol (in fact, we can even elect to use something like Byzantine Paxos which provides additional protections if we’re really paranoid).
What about network partitions?
Both Paxos and Raft are equipped to deal with the problem of network partitions; depending on the exact nature of the problem, some sponsoring servers may be unable to update the state of the group chat while the partition is in effect, but all servers should reach an eventually consistent view of the state. Messages sent while partitioned can simply be queued, and resent once the network link reestablishes itself.
How do we figure out which servers should be sponsoring servers?
The rules will probably vary depending on the circumstances – for example, a private group chat where all members trust one another can have all participating servers be sponsoring servers. In contrast, large, public group chats, with potentially lots of untrusted servers taking part, can choose a small number of servers which they trust – servers which contain chat administrators would be a good target, seeing as a great deal of trust is placed in those servers anyway.
Here’s an example policy: if users are invited by a pre-existing administrator of the room, their server becomes a sponsoring server. If users ask to join a room (by talking to one of the existing sponsoring servers), their server does not become a sponsoring server. That way, new sponsoring servers are added organically; if you’re inviting someone, you presumably trust them and their server anyway. (However, as I said, this may not be the only way of doing things.)
Networking considerations
We can also go and look back at the networking improvements mentioned earlier, and fit these in to our sponsoring-server model. For one-to-one private conversations, it makes a certain degree of sense to just connect the two communicating servers directly – while this may be somewhat more resource-intensive than having some linked network which the messages could travel through, doing it any other way would raise privacy concerns, as well as issues of trust (how can you be sure that the 3rd-party server you’re relaying messages through is actually delivering them and sending you the responses, for example?).
However, group chats are now free to use one of the protocols mentioned earlier (e.g. Ethernet Spanning Tree Protocol) for routing messages, but only amongst the sponsoring servers. So-called ‘leaf’ servers (ones that aren’t sponsoring) must connect to a sponsoring server and communicate via it. This model makes the network slightly less painful than full-mesh: leaf servers only ever need to talk to sponsoring servers (making group chat involvement less of a pain for them), while sponsoring servers deal with their own batch of leaf servers, and route messages intelligently to other sponsoring servers.
Conclusions
This blog post proposes a new model for handling distributed state in chat protocols, which involves choosing a set of trusted “sponsoring servers” for each group chat. These servers are responsible for maintaining consensus about the state of the chat (through consensus algorithms like Paxos or Raft), and act as the ‘gatekeepers’ for new messages and state changes, providing a bunch of helpful functionality against spam and abuse.
I believe this new model is a sort of compromise solution that makes the protocol less complex, but still distributed and somewhat fault-tolerant, at the expense of requiring users to trust some servers/people not to be malicious. Of course, at this point, this is mostly speculation8; I’ll have to write some code and see how it actually works in the wild, though!
-
Here’s where things get interesting; instead of blithely criticizing other people’s hard work, I’m actually having to do some myself… ↩
-
A counterargument might be, as before, “we already have the Internet Protocol to do networking things, so why should we bother implementing more stuff on top of that?” ↩
-
An open federation obviously needs to account for the fact that all servers might not behave. ↩
-
The protocol linked in this paragraph is their new state resolution algorithm, which prevents all of the security issues that plagued the first iteration and that I ranted about originally. ↩
-
Maybe something like Keybase Chat isn’t, but I’m pretty sure all the mainstream ones don’t have this property. And for good reason; doing your own public/private key management as a user is painful, or rather something that most users don’t seem to bother with at present. ↩
-
This is how I first heard about it! ↩
-
Citation: some random person on HN ↩
-
If anyone who actually reads this blog and reckons they know stuff feels like chiming in in the comments, that would be much appreciated! ↩