BTRFS stress test: are the rumors of lost data and unrecoverable arrays true?
This was a post orignally made on Medium back in 2015, when I didn’t have my own blog yet. Fun times!
So you’ve heard of btrfs. It’s the cool new filesystem with great promises: to oneday beat ZFS on Linux and at even exceed its featureset, to use this new-fangled Copy on Write (CoW) technology to do amazing things, to use its own RAID implementation to do not just block-level RAID, but to at one point have differing file-level RAID profiles!
There’s just one problem.
Stability
Is btrfs stable?
Short answer: Maybe.
The official answer is reasonable — after all, how can anyone “magically stick a label on the btrfs code and say “yes, this is now stable and bug-free”? Because btrfs hasn’t been used for that long in a production environment without any major mishap, not many people are willing to trust it with their mission-critical data just yet.
I had a Raspberry Pi, a microSD card for it, a USB stick, and some other stuff around, and decided to do a stress test: I would use btrfs as the Pi’s rootfs, add the USB stick to it in raid1, and do Evil Things(tm) to it whilst it was trying to do stuff. Partly for fun, partly because I was bored, and partly as practice for when something critical fails.
Filesystem creation
This step was easy enough —I already had btrfs running on this Pi after using it with a webcam to take photos of my cat, so adding the USB to it was a simple command:
btrfs device add /dev/sda1 /
The next step was converting to RAID1: a little slow on a Raspberry Pi, but not that hard to do.
btrfs balance start -mconvert=raid1 -dconvert=raid1 /
Evil Things: Round 1
I started writing some sample data to the FS, using dcfldd:
dcfldd statusinterval=1 if=/dev/urandom of=/testfile
So far so good. Whoops, I accidentally pulled the USB stick out! Apart from getting some fun messages in syslog, everything seemed peachy.
BTRFS: bdev /dev/sda1 errs: wr 7, rd 0, flush 0, corrupt 0, gen 0
Round 2: FIGHT!
Looks like it can handle the USB being taken out fine. But what if I take out the microSD card? Bam! Does the same thing as before, except this time, it waits a few seconds and then dumps a whole menagerie of errors out.
Core btrfs errors:
[ 1299.168326] BTRFS: bdev /dev/mmcblk0p2 errs: wr 10, rd 21, flush 0, corrupt 0, gen 0
[ 1302.813900] BTRFS: error (device mmcblk0p2) in btrfs_commit_transaction:2068: errno=-5 IO failure (Error while writing out transaction)
[ 1302.847055] BTRFS info (device mmcblk0p2): forced readonly
[ 1302.896641] BTRFS warning (device mmcblk0p2): Skipping commit of aborted transaction.
[ 1303.736954] BTRFS: error (device mmcblk0p2) in cleanup_transaction:1692: errno=-5 IO failure
[ 1330.470783] btrfs_dev_stat_print_on_error: 618 callbacks suppressed
[ 1303.809130] BTRFS info (device mmcblk0p2): delayed_refs has NO entry
journald decided to be extra helpful in this situation and spam syslog for every message that was posted:
[ 1302.865252] systemd-journald[121]: Failed to truncate file to its own size: Read-only file system
[ 1302.928273] systemd-journald[121]: Failed to truncate file to its own size: Read-only file system
[ 1303.007250] systemd-journald[121]: Failed to truncate file to its own size: Read-only file system
OK, that’s not very good — it just decides to give up the ghost, without any attempt to failover to the other device, or do anything helpful.
Well, that didn’t take very long to break.
Cleaning up the mess
I had previously created and mounted an ext4 backup partition on the USB stick, and copied /usr/bin to it, so I had some working tools (and most libraries were still in disk cache). Right, here we go:
$ ls /
bash: /usr/bin/ls: Input/output error
$ mount
bash: /usr/bin/mount: Input/output error
$ /emerg/bin/mount -o remount,degraded /
No can do, I’m afraid. btrfs currently does not let you remount the filesystem after errors have occured. I’m guessing this is some sort of safety feature, but there doesn’t seem to be a way to override it.
(It also doesn’t help that journald is spewing errors everywhere, so I can’t see what I’m doing.)
One reboot later
[150158.931014] BTRFS: failed to read the system array on mmcblk0p2
[150158.955657] BTRFS: open_ctree failed
PANIC: VFS: Cannot open root device "/dev/somethingorother" in unknown-block(0,0)
Multi-device support for btrfs at boot has never seemed to work for me, even after adding very many “btrfs dev scan” lines to my initrd; I’ve always had to manually mount the fs.
Except I can’t, because this is a Raspberry Pi, which doesn’t have an initrd.
Well that’s just ideal.
A lot of faddling about later
I plug the SD card into my main machine. Same error. Run their fsck-like tool:
$ sudo btrfs check --repair /dev/sde2
Then, trying with -o degraded, it (sort of) works. Change the /boot/cmdline.txt to specify that as mount option, and set root=/dev/sda1 (because that’s the last device to come up), and it boots! (With a lot of “missing csum” and “bad tree block” errors…)
Until journald starts up, and then journald starts. Apparently, the hulking beast that is systemd’s journal is too much for our tiny crippled filesystem, and it balks.
[150222.684619] BTRFS info (device sda1): forced readonly
Go go gadget computer
So the Raspberry Pi gave up the ghost. Let’s try my actual computer.
$ sudo mount -o degraded,recovery /dev/sde2 mnt/
[151180.441479] BTRFS info (device sde2): allowing degraded mounts
[151180.441488] BTRFS info (device sde2): enabling auto recovery
[151180.441490] BTRFS info (device sde2): disk space caching is enabled
[151180.441492] BTRFS: has skinny extents
[151180.455200] BTRFS: bdev (null) errs: wr 354, rd 0, flush 0, corrupt 0, gen 0
[151180.463743] BTRFS: too many missing devices, writeable mount is not allowed
[151180.513782] BTRFS: open_ctree failed
Another little safety feature: btrfs won’t let you go below the minimum amount of devices for raid1 and have a rw filesystem.
$ sudo mount -o degraded,recovery,ro /dev/sde2 mnt/
Yay, it mounts successfully — and yes, I can see (and copy off) my data. I make a quick backup of the cat pics.
Returning the array to working order
I still have the other drive, so I can plug that in and mount the filesystem writably.
Now about all these pesky errors. btrfs comes with a built in tool to fix corruption online, so let’s run that.
$ sudo btrfs scrub start -B gooseb
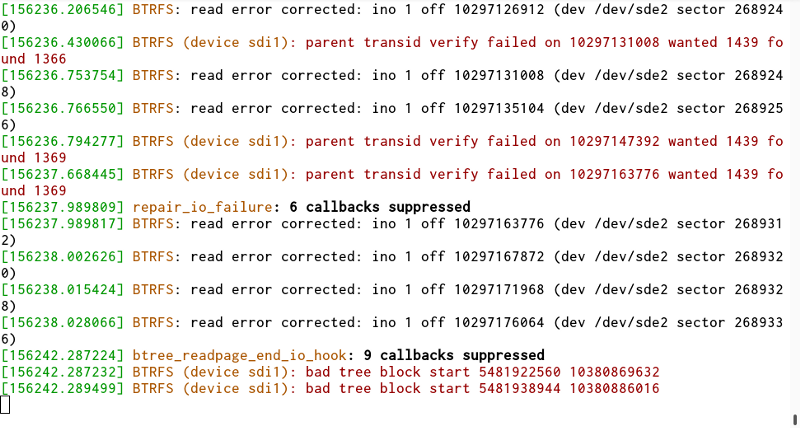
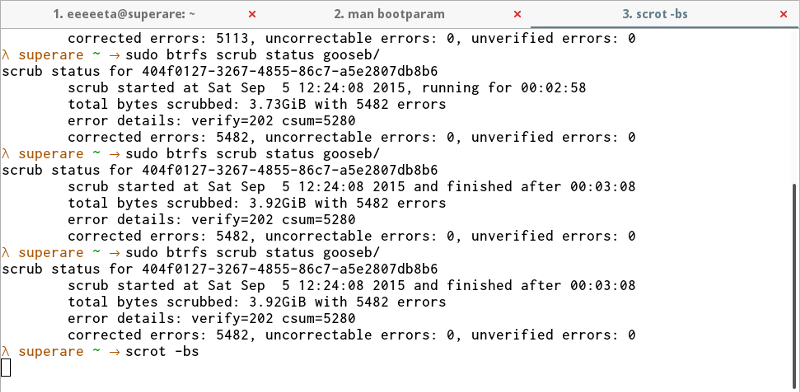
Let that hum for a while, and it appeared to correct all my errors — I was then able to mount the fs on my computer and use it without any sort of problem whatsoever.
Summary
So, btrfs is terrible at recovering from errors live. Like, shockingly terrible. While md-raid will simply just carry on and email you if a drive dies, btrfs will explode in a massive fire and render the entire fs unusable until you fix it with another computer.
But!
Even after being mauled by a malfunctioning Raspberry Pi (or perhaps itself — I’m not sure why there was so much corruption), btrfs managed to pick itself up, correct its errors, and carry on going. That’s impressive — mdraid would have likely not noticed, or copied the corruption to the other drive.
I don’t think btrfs has many issues with fs-caused unrecoverable data (touch wood — btrfs is currently being used on all my boxes) nowadays, as it proved it could handle that pretty well.
The online-recovery stuff can always be built in later, after all.